
Redis 是一个高效的内存数据存储系统,它提供了多种丰富的数据结构。每种数据结构的底层实现是其高性能的关键,理解这些实现有助于我们更好地利用 Redis 来优化我们的应用程序。
1. 字符串(String)
底层实现:
在 Redis 中,字符串的底层实现使用 SDS(Simple Dynamic String)。SDS 是一种动态字符串实现,避免了传统 C 字符串使用 \0 结束符的方式,从而避免了内存碎片问题。它具有以下特点:
- 动态扩展:SDS 可以根据需要动态调整其大小,支持扩展和收缩操作。
- 预分配空间:SDS 会预留一定的内存空间(一般为当前字符串长度的一倍),避免频繁的内存分配。
- 保存长度:SDS 在内存中记录了字符串的长度,避免每次计算字符串长度。
- 安全性:与 C 字符串不同,SDS 存储的数据不包含空字符,因此不存在缓冲区溢出问题。
底层操作:
- 插入/更新:在字符串操作时,Redis 会首先检查是否有足够的空间,如果空间不足,Redis 会扩展 SDS 的容量。
- 内存管理:由于 SDS 是动态分配内存的,因此在 Redis 的内存管理中,SDS 负责管理字符串的内存,包括扩容和释放。
常用场景:
- 缓存存储:如缓存网站的 JSON 数据、API 响应等。SDS 让 Redis 在读取和写入时高效且灵活。
- 计数器:如用户访问次数、点赞数等,Redis 字符串的增减操作非常高效,适合做计数器。
2. 哈希(Hash)
底层实现:
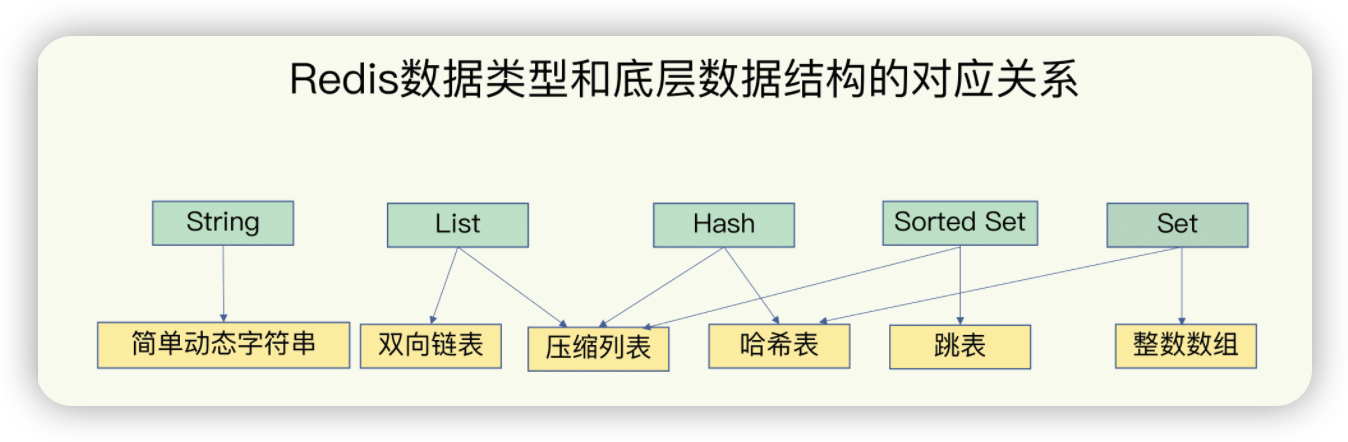
Redis 的哈希使用了两种实现方式:哈希表(HashTable) 和 压缩列表(Ziplist)。
- 哈希表:哈希表是 Redis 默认的实现方式,当哈希的字段数量较多时,Redis 会采用哈希表来存储键值对。哈希表的实现是典型的开放地址法,它通过计算哈希值来决定每个键的存储位置。
- 压缩列表(Ziplist):当哈希表中的元素数量较少时,Redis 会使用压缩列表(Ziplist)来节省内存。Ziplist 是一种连续内存区域,它将数据压缩存储,适合小数据量且较频繁访问的情况。
哈希表的实现:
- Redis 中的哈希表通过 数组 + 链表 结构来实现。数组的每个元素是一个链表头节点,每个链表节点存储键值对。哈希冲突时,哈希表会使用链地址法(链表解决冲突)。
压缩列表的实现:
- Ziplist 是 Redis 内存优化的结果,它采用紧凑的内存布局,存储连续的元素,节省了内存开销,适合存储小量键值对。
常用场景:
- 对象存储:哈希适合存储对象(如用户信息),每个字段作为哈希的键,字段值作为值。
- 会话管理:可以用哈希来存储每个用户的会话信息。
- 高效存储小数据量:当数据较小且查询操作较频繁时,Ziplist 可以有效节省内存。
3. 列表(List)
底层实现:
Redis 列表使用了 双向链表(Doubly Linked List) 和 压缩列表(Ziplist) 这两种数据结构。具体选择哪种结构取决于列表的大小:
- 双向链表:当列表中元素数量较多时,Redis 使用双向链表实现,允许从列表的两端高效插入和删除元素。每个链表节点包含三个字段:前一个节点指针、后一个节点指针和数据。
- 压缩列表(Ziplist):当列表中的元素较少时,Redis 会使用压缩列表,它将数据以紧凑的方式存储,减少内存开销。
常用场景:
- 消息队列:由于双向链表能够支持从两端插入和删除数据,因此非常适合用作队列的实现(如任务队列、消息队列)。
- 聊天记录、评论列表:列表支持从头部和尾部插入数据,适合存储有序的消息数据。
4. 集合(Set)
底层实现:
Redis 集合的底层实现使用了 哈希表(HashTable) 或 整数集合(IntSet)。
- 哈希表:如果集合中的元素是字符串或者其他复杂类型,Redis 会使用哈希表来存储集合元素。
- 整数集合(IntSet):如果集合中的元素是整数,Redis 会使用整数集合来进行优化。整数集合是一种紧凑的内存结构,它通过位图的方式存储整数,极大减少内存占用。
常用场景:
- 去重:Redis 集合天然支持去重操作,适合存储无序、唯一的元素。
- 社交网络:集合可以用来表示用户的关注列表、好友列表等,因为集合的插入和查找操作都是 O(1) 时间复杂度。
- 标签、推荐:集合可以用来存储多个标签,并支持集合运算,如并集、交集、差集。
5. 有序集合(Sorted Set)
底层实现:
有序集合是 Redis 提供的一种支持排序的集合,底层实现结合了 跳表(SkipList) 和 哈希表(HashTable)。
- 跳表(SkipList):跳表是一种高效的数据结构,它通过多级索引来实现快速查找和排序。每个元素都保存了一个分数(score)和一个值(value),跳表通过分数值对元素进行排序。
- 哈希表:哈希表用于存储每个元素的值和值对应的分数,确保有序集合中的每个元素是唯一的。
跳表通过多层索引实现了 O(log N) 的查找和插入复杂度,因此在大规模数据操作时,Redis 的有序集合能保持较高的性能。
常用场景:
- 排行榜:Redis 的有序集合非常适合用来实现排行榜,如游戏的分数排行榜、用户活跃度排行榜等。
- 时间戳排序:通过分数来表示时间戳,有序集合可以实现按照时间排序的任务队列。
- 延迟任务调度:通过有序集合,可以按时间戳来调度任务,支持延迟执行和任务的定时执行。
总结
Redis 的底层实现非常精妙,不同数据结构的实现方式依据其使用场景和性能需求进行了优化。理解这些底层实现可以帮助我们在实际开发中更好地选择合适的 Redis 数据结构,确保高效的内存管理和快速的数据访问。
常用场景与选择:
- 字符串:缓存、计数器、会话存储。
- 哈希:存储对象、会话管理、稀疏数据存储。
- 列表:消息队列、聊天记录、历史记录。
- 集合:去重、社交网络关系、集合运算。
- 有序集合:排行榜、延迟队列、时间戳排序。
理解 Redis 的底层实现原理以及其常用场景,将帮助我们根据实际业务需求选择最合适的数据结构,从而最大化 Redis 的性能优势。